


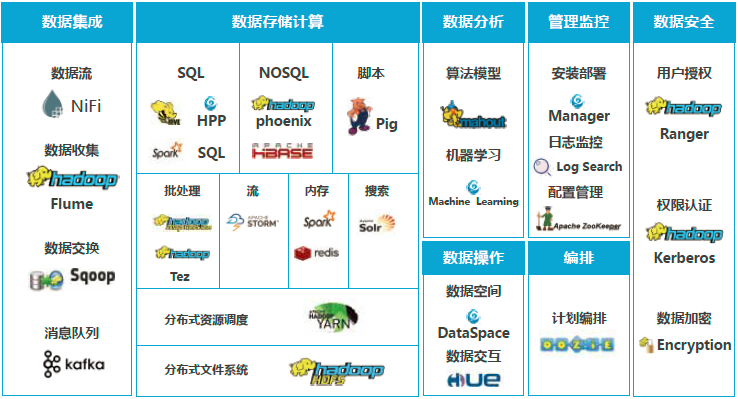
超越云巔CyInsight ,是一套經過調優和功能增強的Hadoop與Spark企業發行版,包含Hadoop生態中的20+主要組件,幫助客戶輕松應對海量數據的采集、存儲、計算、分析挖掘和數據安全等應用場景
多源數據的高效集成
云巔CyInsight 提供多源數據(包含結構化、半結構化和非結構化數據)的集成能力,提供高吞吐、可擴展的數據總線和數據分發功能,支持批量加載、實時加載、數據庫加載、文件加載等多種加載方式。
異構數據的海量存儲
云巔CyInsight 提供基于分布式文件系統和并行架構的大數據存儲能力,支持PB級數據規模的高可靠和高可用存儲,支持存放多種文件格式,例如關系數據庫等結構化數據,日志、網頁等半結構化數據,以及視頻、圖片、文檔等非結構化數據。
多場景下的數據計算框架
面向不同業務場景,云巔CyInsight提供離線計算、流式計算、內存計算、圖計算等豐富的計算框架,支持計算任務流程編排、計劃安排,提供標準SQL的數據訪問能力。
基于機器學習的大數據分析
云巔CyInsight 提供涵蓋多源數據接入、數據特征提取、算法模型管理、算法模型評估和結果預測等完整機器學習過程的可視化大數據分析功能。支持多元分類、回歸分析、協同推薦等分析模式,SVM、樸素貝葉斯、K-Means、線性回歸等10+種算法,支持批量預測和實時預測功能并提供API。預測過程基于內存進行迭代式計算,并且支持分布式計算,可以應對海量數據分析。
安全有效的資源隔離與共享
云巔CyInsight 提供對結構化、非結構化數據的多用戶資源管理,滿足對數據資源的權限隔離、安全授權和資源調度。提供多用戶的可視化數據空間管理功能,支持數據空間大小、文件數、計算隊列等的配額設置;支持多用戶間數據資源的開放訂閱和指定共享,共享權限可控制到文件目錄、表及列族級;支持對數據訪問的審計和監控。
統一的大數據平臺運維管理
云巔CyInsight 提供針對HDFS、MapReduce、Hive、HBase、ZooKeeper、Oozie和Spark等20+組件的自動化安裝部署,并為平臺提供完善的配置管理、監控告警等能力。
產品詳情
產品參數
1、 性能指標
測試環境:8節點集群;節點典型配置:CPU:2*E5-2640,內存:256G,硬盤:SATA盤
|
分類 |
指標項 |
規格 |
|
|
MapReduce性能指標 |
WordCount:平均每節點處理能力
|
8GB/分鐘 |
|
|
Terasort:平均每節點處理能力 |
6.4GB/分鐘 |
||
|
Spark性能指標 |
WordCount:平均每節點處理能力 |
30GB/分鐘/Node |
|
|
Terasort:平均每節點處理能力 |
9GB/分鐘/Node |
||
|
SQL on Hadoop |
Aggregation:平均每節點處理能力 |
8GB/分鐘 |
|
|
Join:平均每節點處理能力 |
4GB/分鐘 |
||
|
HBase |
100%隨機讀:平均每節點讀取記錄條數(每條記錄1KB),響應時間小于50MS |
30,000 Records/s |
|
|
100%隨機寫:平均每節點寫入記錄條數(每條記錄1KB),響應時間小于50MS |
40,000 Records/s |
||
|
順序掃描:平均每節點scan記錄條數(每條記錄1KB),響應時間小于50MS |
15,000 Records/s |
||
|
50%隨機寫+50%隨機讀:平均每節點寫入記錄條數(每條記錄1KB),響應時間小于50MS |
寫25,000 Records/s 讀18,000 Records/s
|
||
|
50%隨機寫+50%掃描讀:平均每節點寫入記錄條數(每條記錄1KB),響應時間小于50MS |
寫30,000 Records/s 讀10,000 Records/s
|
||
2、產品兼容性
2.1 CPU兼容性
超越云巔CyInsight大數據平臺兼容主流硬件架構:X86、ARM
2.2 操作系統兼容性
|
序號 |
操作系統 |
|
1 |
CentOS |
|
2 |
Redhat |
|
3 |
銀河麒麟 |
|
4 |
中標麒麟 |
|
5 |
麒麟OS |
|
6 |
EulerOS |

